我训练emlight很长时间了,在小规模数据集上尚能收敛,数据集规模一上升到18000就失控。由于现在很多论文里公布的方法本就无法复现出作者描述的效果,再加上对神经网络弊端的一些了解,emlight在大规模数据集上难以收敛的问题,我也就没有多加怀疑。
结果上周发现emlight作者上传了一个叫geomloss的包,而这个包本来在python的pip库里有官方版本。由于我是在作者上传之前就fork并下载源代码的,后来也没多想作者这个动作,我一直用的是都是官方版本。上周用相同的输入测试作者上传的geomloss和官方的,结果发现输出不一样。这意味着作者自己无声无息地改写了geomloss包。于是我将官方的geomloss删除,换成了他的,重新开始训练。
emlight的loss设计分为三部分:
1 | loss = dist_emloss + dist_l2loss + intensity_loss + rgb_loss + ambient_loss |
dist_emloss + dist_l2loss是光参数里的“光分布”,它表示球面空间上光源的位置和相对亮度。intensity_loss + rgb_loss是光源的整体强度和颜色。ambient_loss是环境光。上述geomloss包是用来计算dist_emloss的。
更换之后的训练结果
仍然采用数据集“由小到大”的策略循序渐进地训练emlight,分别在100、1000、2500、10000 上训练emlight,看训练的loss曲线:
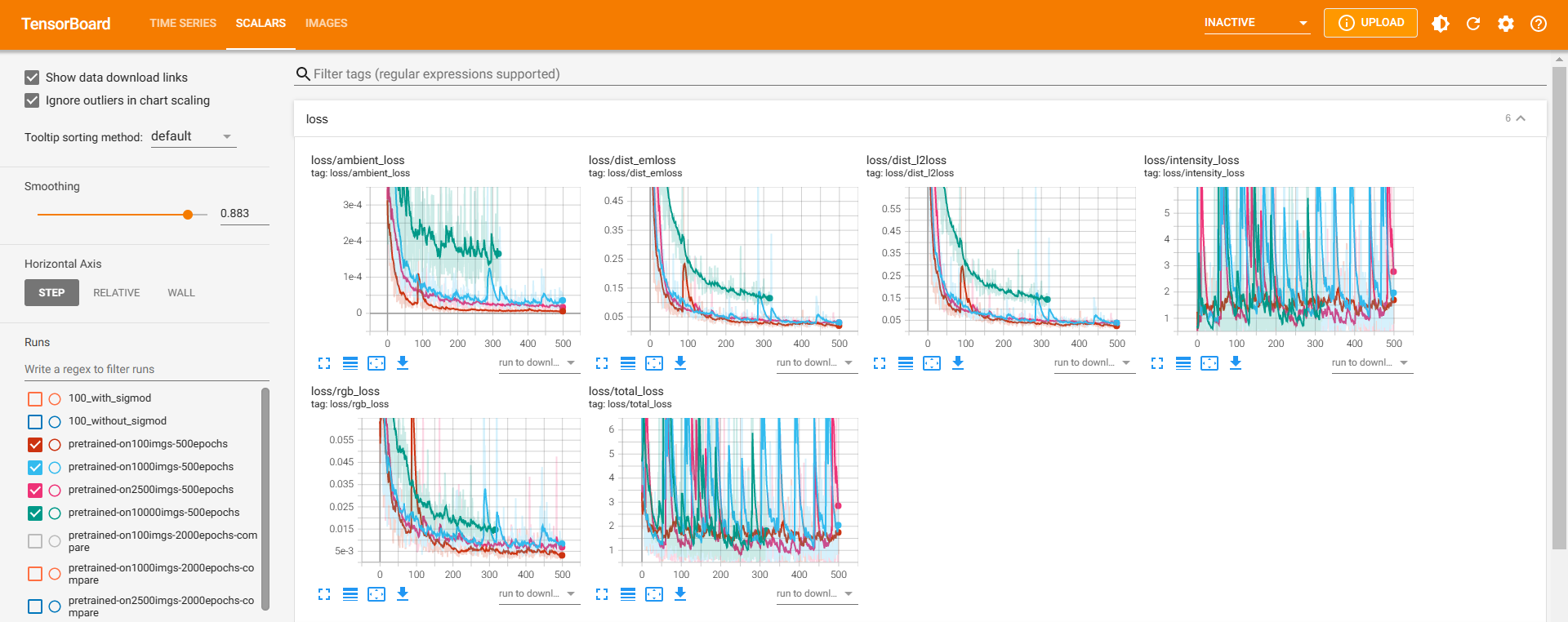
图片左侧标明了四条曲线是在哪种规模数据集上训练的。可以看出,更换了geomloss为作者版本之后,在四种规模数据集上训练的loss基本是重合的,随着数据集规模的增大loss曲线有整体上移的趋势,但上移不大。
与更换前的训练记录对比
在更换geomloss之前,我也在这几种规模数据集上训练过。可以将之前的记录显示到这六张loss子图上,对比观察出一些结论。下面依次将之前的训练结果按照数据集由小到大的顺序展示在上图中:
规模=100(灰色曲线)
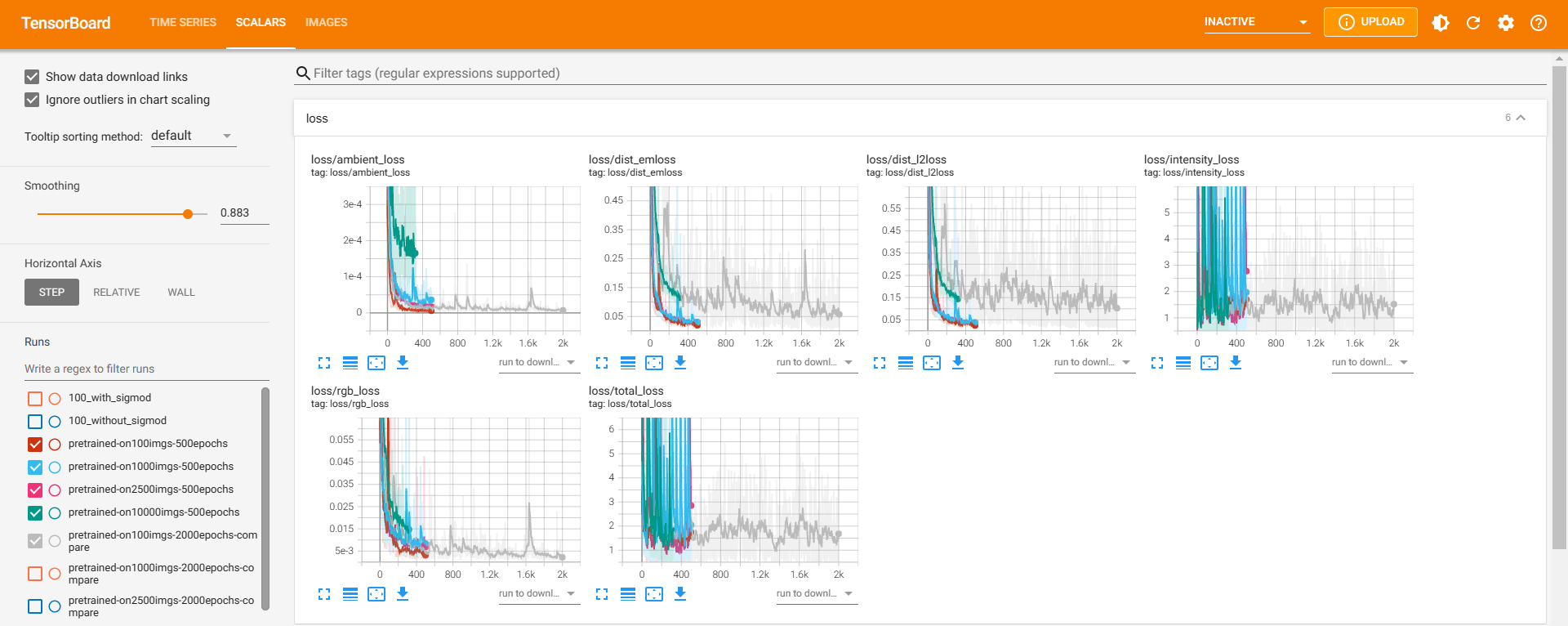
规模为100的loss与更换geomloss之后的四次训练基本重合。
规模=1000(橙色曲线)
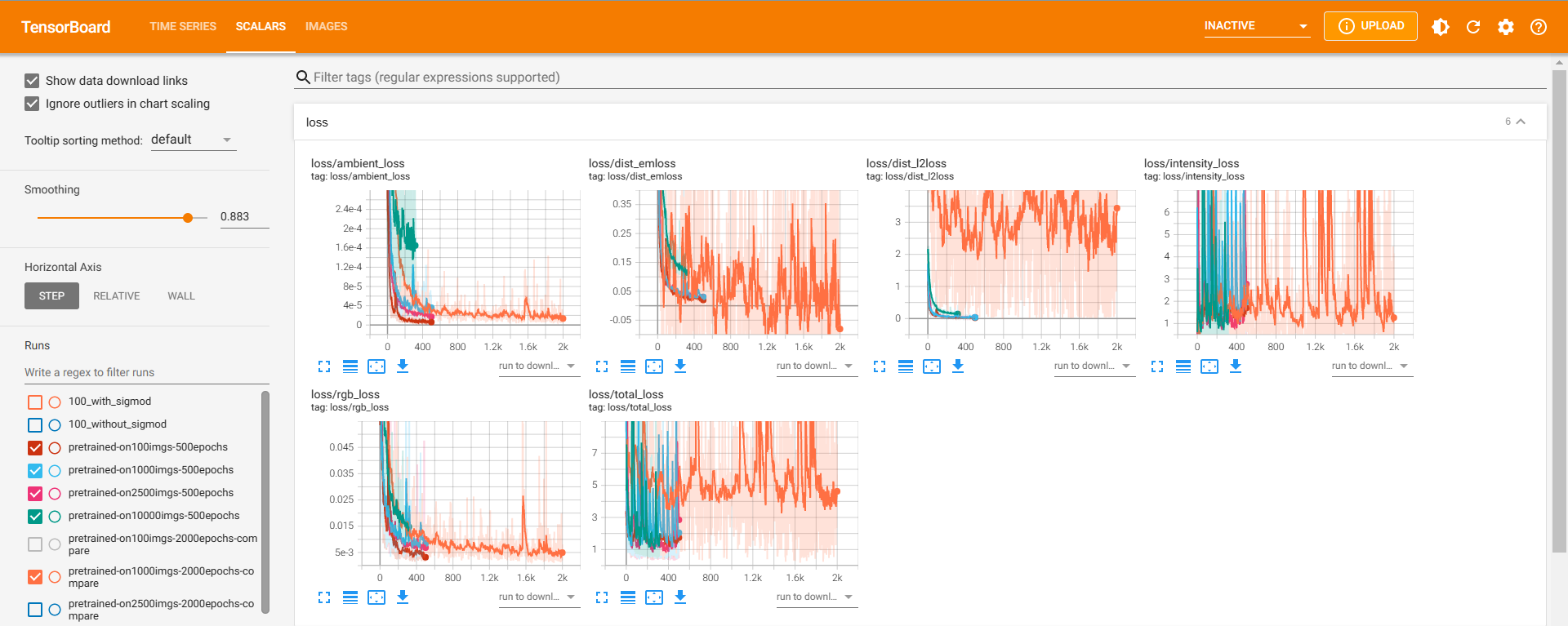
total_loss开始整体上移,其原因应当是dist_l2loss分量的整体上移。dist_l2loss虽然不是geomloss直接计算的,但是倘若geomloss所计算的dist_emloss不对光分布的正确预测起作用或起到反作用,那么dist_emloss下降一定会引起dist_l2loss无法下降。
规模=2500(蓝色曲线)
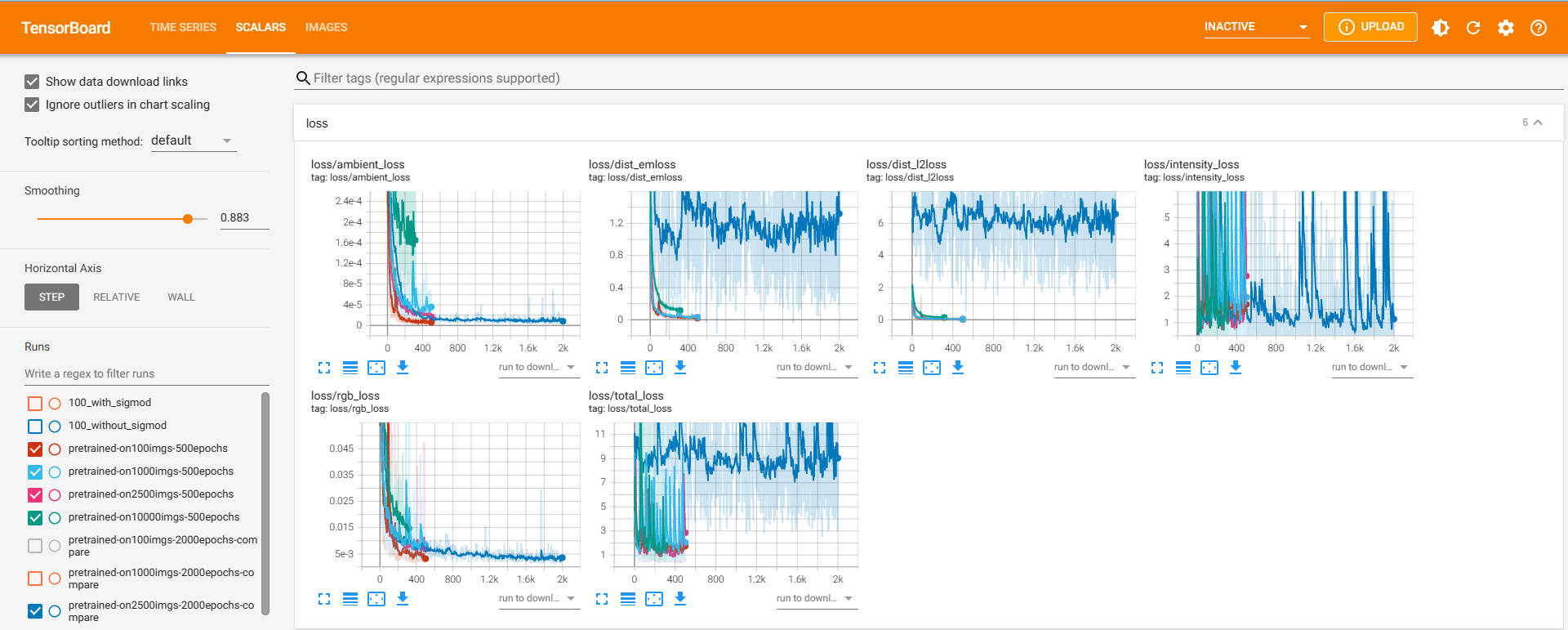
total_loss与四条曲线的差别更大了。此时dist_l2loss和dist_l2loss同时上移,它们也是total_loss上移的主要原因。此时光分布难以被正确预测,而环境光、光源总强度却能预测得与四条曲线一致。
规模=10000(红色曲线)
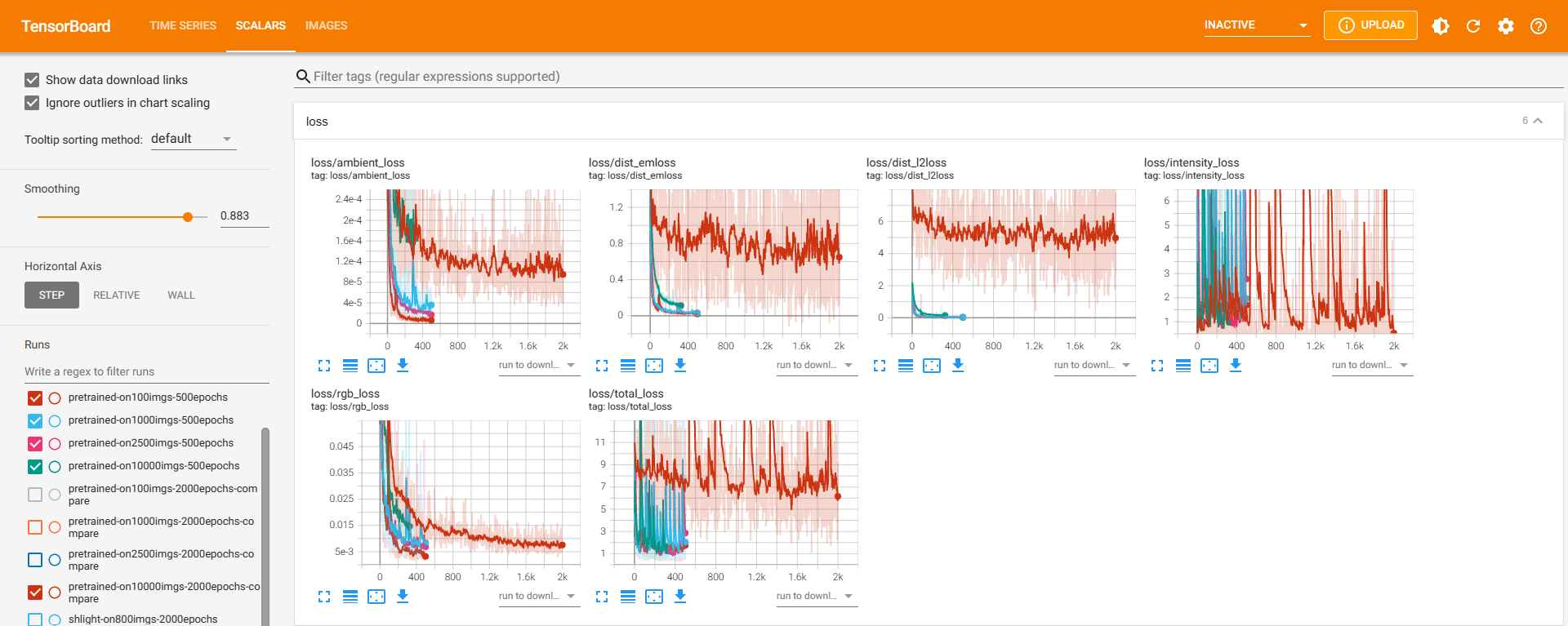
10000的loss情况和2500很像,都是dist_l2loss和dist_l2loss的上移导致total_loss上移。10000的上移甚至比2500好一点,这个我暂时解释不了。
总结
总而言之,本文通过实验观察了当总loss中有一个分量的设计不合理、计算错误时会对训练造成的影响。(当网络采用的是emlight所用的densenet时,)暂且总结出以下几点:
- 最终:错误的loss项会误导网络,导致训练不出想要的结果
loss是用来指挥神经网络梯度下降的,给神经网络设一个错误的loss就好比给路人指了错误的方向,结果可能是走了很多弯路,甚至南辕北辙。 - 短期看:loss下降不代表loss的设计有意义
total_loss是由很多个loss分量组成的,其中一个分量无意义,但其他分量有意义,此时神经网络仍然可能在有意义的loss分量的指挥下一直梯度下降。在规模为100的数据集上训练,loss与更换geomloss之后的四次训练基本重合,从loss的下降过程来看训练一切顺利。这说明在网络够深而数据集够小的情况下,哪怕你的loss设计得没有意义,loss也会下降。这种下降并不代表网络在loss指引下学到了“规律”(规律指的是输入和输出之间的联系),而仅仅是大力出奇迹,网络被迫记忆了每一张图片及其正确输出。 - loss之间:错误的loss分量可能不影响其他正确loss分量的下降
上面的对比中,更换geomloss之前的四次训练,环境光、光源强度等loss分量的下降均与更换更换geomloss之后的四次训练吻合。不同的唯有光分布对应的dist_l2loss和dist_l2loss两项。