前言
z博士让我去找一些精美的模型,放到blender里作为teaser。我寻思着着这和定性评估用的VOR差不多吧,就是模型要找些更精致的。z博士还给我看了个例子:

于是我打开blender,开干。
第一次尝试
起初,我打算用与VOR不一样的方法。因为VOR是阿里里面专业美工做出来的,在blender里如何放置物体、设置材质、设置相机什么的,我其实都不太熟悉。所以,我最开始希望摆脱既有的做法(我难上手),直接插入全景图作为环境贴图提供光照,然后插入物体,最后渲染。
这里我是想着结果好看就行,既然是teaser应该不用保证别人能够复现并比较吧。我挑了一个工坊一样的场景,并放置了一个机器人在中间: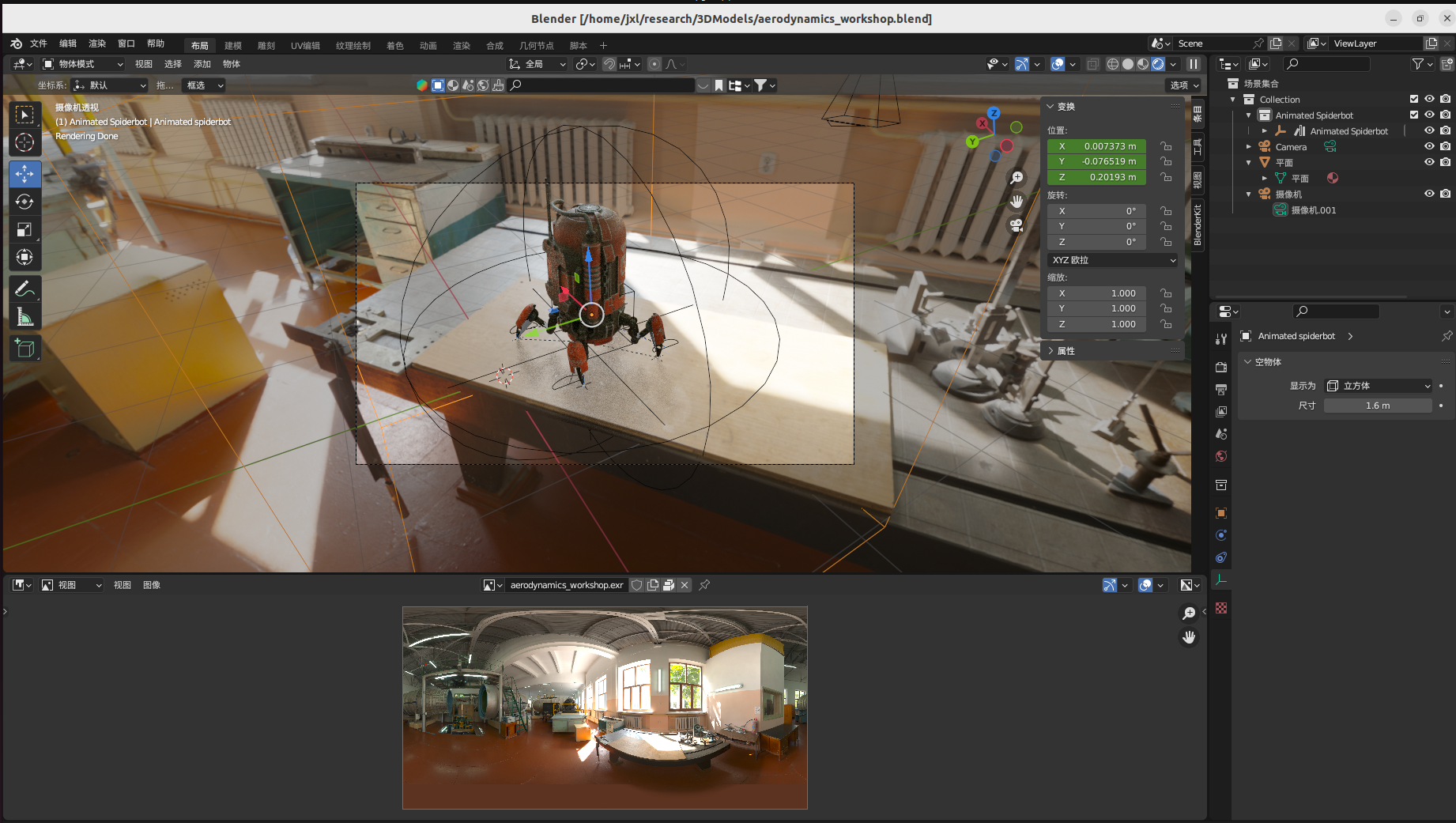
机器人的下面有个透明的板子接受阴影。做到这一布我已经知道如何放置“透明”底板了,看到逼真的结果也很开心。
但是后来想想我又有担心,因为从来没有做过这样的事情,思路又往对比实验上面走了。我开始思考如何从构建好的工程中提取crop和以crop为中心的全景图(和插入时的不一样的全景图),以“严谨地”能够让别人复现。总之,我一开始做了一个很有意思的尝试,但因为和见到过的做法不一样,我退缩了,求稳选择了另外一条路。
第二条路
第二条路就是仿照VOR的做法:
1. 1920*1530的crop作为相机背景,渲染器的输出也设置为1920*1536。在相机属性里,将crop设为背景。
2. 物体下方放置透明平面,平面的材质尽量调成与环境一致的,平面仅用于捕捉阴影
3. 渲染属性->胶片->透明,使得全景图不出现在渲染结果中
4. 利用“合成”节点,将渲染结果上叠到背景图片中
由于手头的数据集都是小尺寸的图,用作背景效果不好,我只能从自己掌握的Web数据集重新制造大尺寸的crop、warped等图片。这个过程相当耗时间。代码改了改,把styleLight自带的warping.py里开玩笑一样的循环逻辑改成np矩阵操作,然后又把还是可复用的xyz矩阵构建过程写成全局的,终于才能在一夜之间处理好web数据集。
最终,我终于掌握了构建像VOR一样的定性评估数据集的能力。展示一些最终的渲染效果:



你能看出哪些是虚拟物体吗?
此时,“从单幅图像估计出场景光照,并逼真地渲染虚拟物体”完成了闭环。看到这些结果还是蛮开兴的。至少在我操作blender的过程中,能够看到我的SHGLight估计出的光照贴图整体上和GT很相近了。这些可都是采集自网络的场景啊!这不就意味着算法有落地的可能性吗?面对从未见过的数据,其预测结果是较为准确且鲁棒的。美中不足的是,估计的结果在亮度上总不如GT。可能因为亮度估计的不适定性确实太强了,我选择的场景GT也都太亮了。
真正的实力
如果得到了上面的结果就以为完成了,还是太young了…
汇报完之后,z博士认为背景图片可以去掉,原因有三个:
- 目前的背景不够好看,作为teaser不算加分。teaser一定要有艺术性,审美够高,一下子抓住人的眼睛,非常impressive。
- 后面最好让物体和灯光都旋转起来,拍成视频展示效果。背景在上面没法旋转。
- 背景和物体放到一块突出不了物体,而我们需要突出重点。
这下我明白了。teaser就像论文的广告,一定要美,吸引人,给人留下深刻的印象。至于能不能让别人重复,不需要考虑。广告嘛,一般都有些夸大成分。要不要和GT比较呢?当然不要,GT的渲染结果跟SHGLight也差不多(勇敢一点,说:我和GT差不多),放了GT也会分散别人的注意力。
总之就是,impressive!