实验室里的服务器都是大伙共用的,最近总是跑得很慢。
发现问题
我们发现,python中导入一个包都要很久。例如,我写了个脚本ioLook.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ## ioLook.py
import time
# 开始记录时间
start = time.time()
import torch
import torchvision
# 结束记录时间
end = time.time()
# 输出导入torch和torchvision包所需时间,单位为秒,保留两位小数
print('导入torch和torchvision包所需时间:{:.2f}s'.format(end - start))
|
它的输出:
1
2
| (emlight) jixinlong@ubun:~/util$ python ioLook.py
导入torch和torchvision包所需时间:187.70s
|
执行一次需要竟然需要187.70s。这表示服务器基本不能用了…
分析问题
决定服务器性能的因素主要是CPU、内存、磁盘。CPU负责一个进程中的计算部分,用于计算的数据直接存储在内存中。但是内存造价过高,因而大部分数据平时是存储在磁盘上的,只有在参与计算时被临时调入内存中。CPU负载过高会导致计算缓慢,内存不足会导致数据频繁调入调出浪费时间,磁盘与内存之间的IO负担过重也会导致IO称为瓶颈。
我们先用htop了解整体情况:
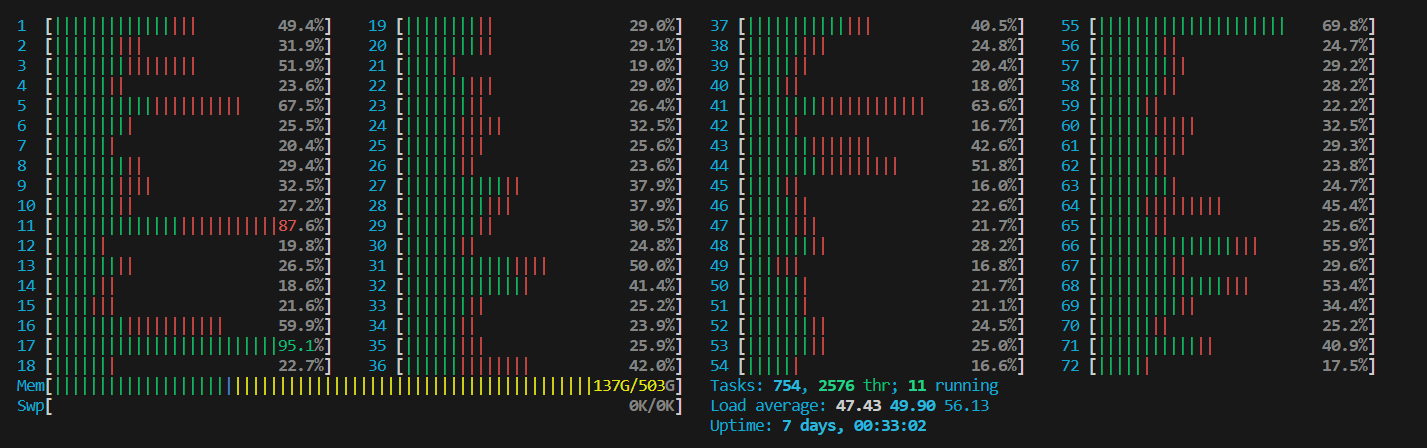
这里可以看到,CPU的利用率整体上低于50%,而内存也有很多的盈余。所以问题不在CPU和内存,那就应该是IO的问题了。再用iostat -x 1看一下磁盘IO的情况:
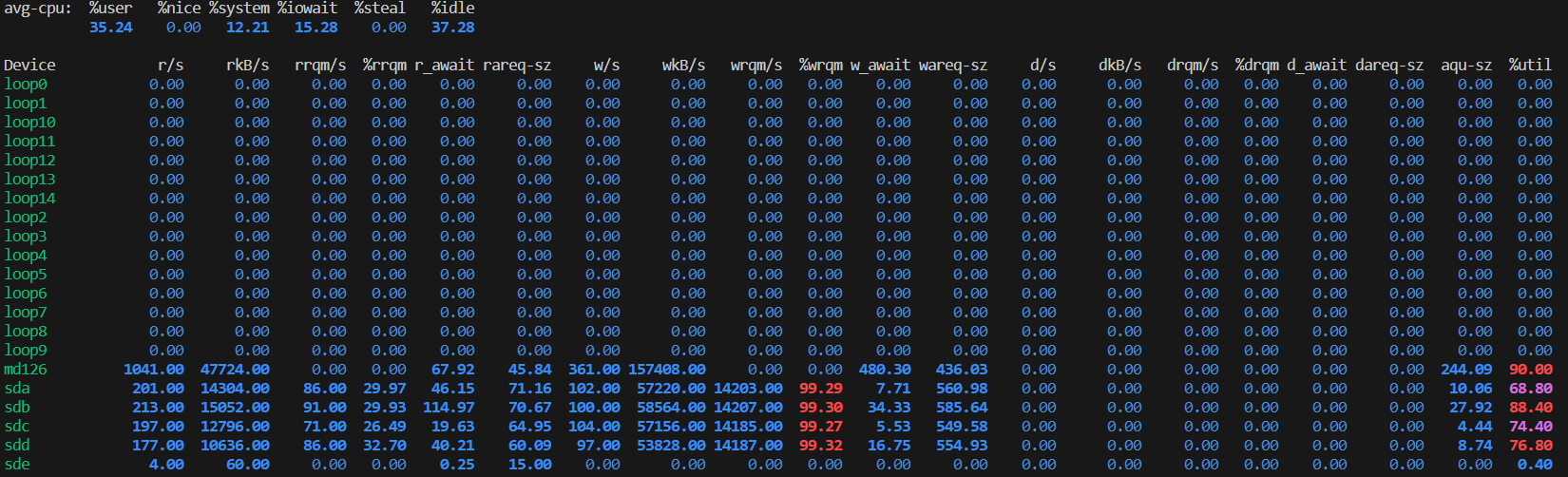
结果的第一行呼应之前对CPU使用情况的观察:用户使用率(%user)在35%,空闲率(%idle)也高达37%。所以绝对不是CPU负载过重了。再看一眼CPU等待IO的时间(%iowait)竟然高达15%,这算是一个很高的值了。这就好比一个加工厂一年中只有35%的时间在干活,37%的时间在放假。这个工厂这么清闲,不是因为它订单少,而是因为它有一个很弱的运输队。其实有一大波订单在等着工厂去做,但工厂的运输队能力很弱,原材料难以运进来,产品也难以运出去,一年有15%的时间都浪费在等着运输队运进运出。
上图中md126那行显示,硬盘md126的写流量比较大(wKB/s),约有157M/s。从这个数值看不出什么,因为我也不知道该硬盘最高读写速度是多少。但是它的IO使用率(%util)已经高达90%了。
我这里只看md126。因为它是数据目录/data对应的硬盘,是所有人放置代码和数据的位置。可以用df -h 命令查看到的硬盘使用情况,/dev/md126 42T 31T 9.1T 78% /data:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| (base) jixinlong@ubun:~/util$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 252G 0 252G 0% /dev
tmpfs 51G 5.4M 51G 1% /run
/dev/sde2 3.5T 2.2T 1.1T 67% /
tmpfs 252G 1.7G 251G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 252G 0 252G 0% /sys/fs/cgroup
/dev/loop0 128K 128K 0 100% /snap/bare/5
/dev/loop1 64M 64M 0 100% /snap/core20/2015
/dev/loop3 92M 92M 0 100% /snap/gtk-common-themes/1535
/dev/loop4 41M 41M 0 100% /snap/snapd/20092
/dev/loop2 74M 74M 0 100% /snap/core22/864
/dev/loop5 41M 41M 0 100% /snap/snapd/20290
/dev/loop6 75M 75M 0 100% /snap/core22/1033
/dev/loop7 46M 46M 0 100% /snap/snap-store/638
/dev/loop11 497M 497M 0 100% /snap/gnome-42-2204/132
/dev/loop13 497M 497M 0 100% /snap/gnome-42-2204/141
/dev/loop8 350M 350M 0 100% /snap/gnome-3-38-2004/143
/dev/loop9 350M 350M 0 100% /snap/gnome-3-38-2004/140
/dev/loop10 64M 64M 0 100% /snap/core20/2105
/dev/loop12 13M 13M 0 100% /snap/snap-store/959
/dev/sde1 513M 6.1M 506M 2% /boot/efi
/dev/md126 42T 31T 9.1T 78% /data
tmpfs 51G 20K 51G 1% /run/user/125
tmpfs 51G 4.0K 51G 1% /run/user/1028
tmpfs 51G 4.0K 51G 1% /run/user/1031
tmpfs 51G 8.0K 51G 1% /run/user/1001
tmpfs 51G 4.0K 51G 1% /run/user/1006
tmpfs 51G 4.0K 51G 1% /run/user/1017
tmpfs 51G 4.0K 51G 1% /run/user/1019
tmpfs 51G 4.0K 51G 1% /run/user/1002
tmpfs 51G 4.0K 51G 1% /run/user/1003
tmpfs 51G 8.0K 51G 1% /run/user/1015
tmpfs 51G 8.0K 51G 1% /run/user/1023
tmpfs 51G 4.0K 51G 1% /run/user/1029
tmpfs 51G 8.0K 51G 1% /run/user/1012
tmpfs 51G 8.0K 51G 1% /run/user/1032
tmpfs 51G 8.0K 51G 1% /run/user/1033
tmpfs 51G 8.0K 51G 1% /run/user/1010
|
df -h 命令的输出还显示,md126这块硬盘非常大,有42T。这么大的硬盘基本是便宜量大的机械硬盘,不太可能是固态硬盘。所以它的IO写入速度才157M/s就达到瓶颈了,我觉得不奇怪。再去网上查查机械硬盘通常的读写速度是多少呢?是80MB/s至160MB/s之间。
分析到这里就差不多了,实验室服务器使用的是机械硬盘,读写速度慢,在同学们训练的时候会大量加载数据或者保存模型。加载数据时要读取磁盘,保存模型要写入磁盘,这两个需求过大时都会触发磁盘IO的瓶颈,导致CPU等待IO的情况。而我import torch其实也是把存储在磁盘上的torch库文件加载进内存,是读取磁盘的过程。而IO过于繁忙,我不得不等个187s。
解决问题
其实我觉得,现在笔记本基本都是固态硬盘了。用习惯了固态硬盘之后,再转到服务器用机械硬盘,确实会觉得机械硬盘百兆的IO读写速度不够用。况且这个服务器还是多人使用的,随便几个人每人占用个10M左右的IO带宽,服务器的硬盘IO就被占满了。
长期看,还是应该换成固态硬盘。固态硬盘是贵一些,但我们可以只把需要用的数据和代码放到固态硬盘上,机械硬盘当作备用存储。
短期看,用sudo iotop查看是谁的进程在大量使用IO,给出意见让其修改代码减少IO。但有些时候大的IO行为就是避免不了的。